Teralytics gave my 5-man team the challenge of figuring out what types of users (in terms of age,
interest, etc) go to each of 1000s of different websites. we were given
nothing
more than a large dataset containing anonymized users and their browsing
patterns. My team developed and implemented a multi-step process,
performing many tasks such as pre-categorizing a subset of the websites by
genre, web-scraping a bunch of the websites for more features, and
developing machine learning models to help with further categorization. I
worked on a lot of these parts and did most of the data wrangling, but the part I'm proudest of (which I did
single-handedly) was developing a fairly robust multi-threaded web scraper
that scraped thousands of websites within a half hour.
My Contribution
I did most of the data-wrangling, engineered the features and training
data for the website
category classifier, and single-handedly wrote a
multi-threaded web scraper in order to scrape 8,000 websites quickly
(within 30 mins). I also wrote a large portion of the final report, and
converted the report into a LaTeX document.
Main Features
Technology I Used
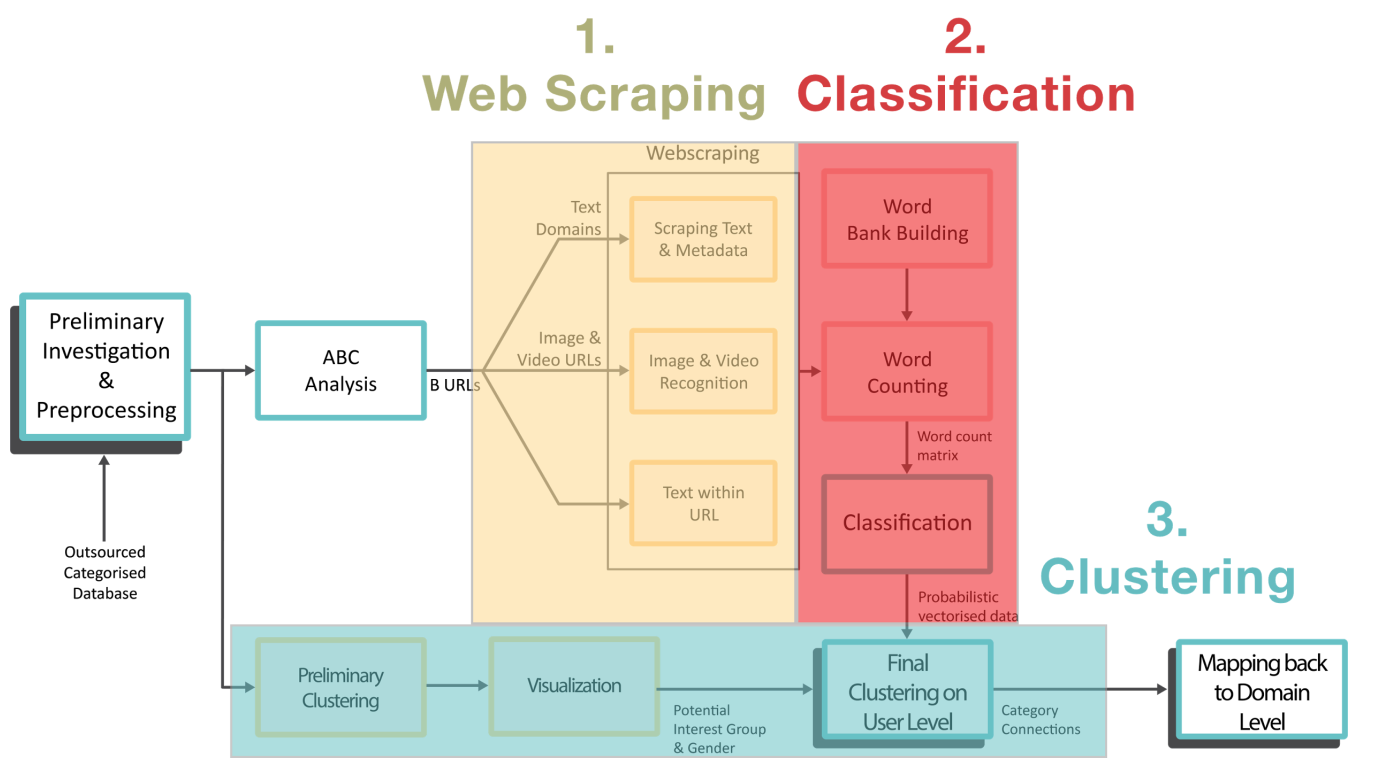
Web-Scraping Challenge
The initial dataset we were provided with had 2 problems: 1) it was
really, really big and 2) it didn't have enough features (only anonymous
user IDs and sites these users visited).
In order to address these problems, we decided to focus on a subset of key websites
that we could scrape for further information (headers, titles and more
information that would clue us in on the website's category). I built the
web scraper from scratch (although afterwards, I found a library that does
multithreaded webscraping quite well). I come from a strong JavaScript background, and
I'm used to dealing with Promises. But in Python, Promises don't seem as
prevalent so I pushed myself to take the opportunity to learn
multithreading instead. It paid off well, and the 8000+ subset of domains
only took half an hour to scrape and process.
Feature Engineering for Website Categorization
We'd managed to obtain a database which categorized a good chunk of the
websites we had. However, there was still a significant amount of websites
which were not in the database, so we needed to build a classifier. We
decided to look at the word frequency count in text such a headers and titles
in each of the uncategorized websites, and, by using the word frequency count
for precategorized websites as a training set, build a classifier
(eventually, we made a decision tree) to take
these counts as features and then output the corresponding categories.
As I was building the training set, my web-scraper came in useful again (I'd made
it very configurable) as we had to scrape 25,000 additional websites. One of
the main challenges I faced was getting the scraped data to process quickly.
A learnt a number of performance optimizations when working with pandas to
achieve this speed. In particular, one of the optimizations that will stick
with me the most is that generating a large dictionary as a temporary data
storage structure for a large number of processed data entries
and then converting that dictionary into a DataFrame is
far quicker than adding a row to a DataFrame for each
processed data entry. This optimization took the processing time down from
minutes to mere seconds.
Interesting Results
Overall, we had over 280,000 unique domains that we needed to gain user
insights for, which is far too many websites to feasibly and scalably scrape. It was pretty interesting that we were able to get good
results for those websites by only web-scraping 8,000+ websites. This was
the B group in ABC analysis. We were able to determine the user base
demographics for these websites, and then, by associating these
demographics with the subset of anonymized users that used these B group
websites, we were able to propagate the results to the remaining users (and
therefore the remaining 270,000+ websites.
There are other interesting results regarding the specific dataset we used,
but those are confidential and I'm quite fairly bound by an NDA not to share them.